
Overview
In-Context Learning (ICL) is a recent paradigm in the field of machine learning which uses Large Language Models (LLMs) for learning and inference. It was first identified in the paper Large Language Models are Few Shot Learners (Brown et al., 2020). ICL enables LLMs to adjust to new tasks without changing any of their internal weights. Instead of retraining or fine-tuning the LLM, we simply provide instructions and examples directly as part of the prompt context. In turn, the LLM processes these demonstrations, detects the underlying patterns, and applies the identified pattern structure to new input queries. ICL requires no explicit training phase, which allows for incremental and online learning. In addition, the LLM may provide human-readable explanations in natural language which justify its generated output. Most importantly, ICL allows for additional domain information to be provided at inference time as inductive bias. For example, when making predictions about the weather, the model may be provided semantic descriptions of the provided features or may be provided prior information about the specific region that is under investigation. More generally the use of ICL enables a single neural network model to seamlessly shift between tasks, e.g., classification, translation, summarization, or reasoning, based solely on the current context. In this website, we introduce the core ideas behind in-context learning and provide a variety of hands-on examples in regression, reinforcement learning, pattern recognition, and translation. All examples are implemented as Google Colab tutorials and can be run using the free Gemini version.
Demos
Explore a collection of interactive demos that show how LLMs can learn patterns, make predictions, classify data, tune controllers, and even perform reinforcement learning — all without retraining, using only In-Context Learning.
Below is a list of all available demos, categorized by color:
- Sequence/Pattern Learning | - Prediction & Regression | - Classification | - Reinforcement Learning & Numerical Optimization
.gif)
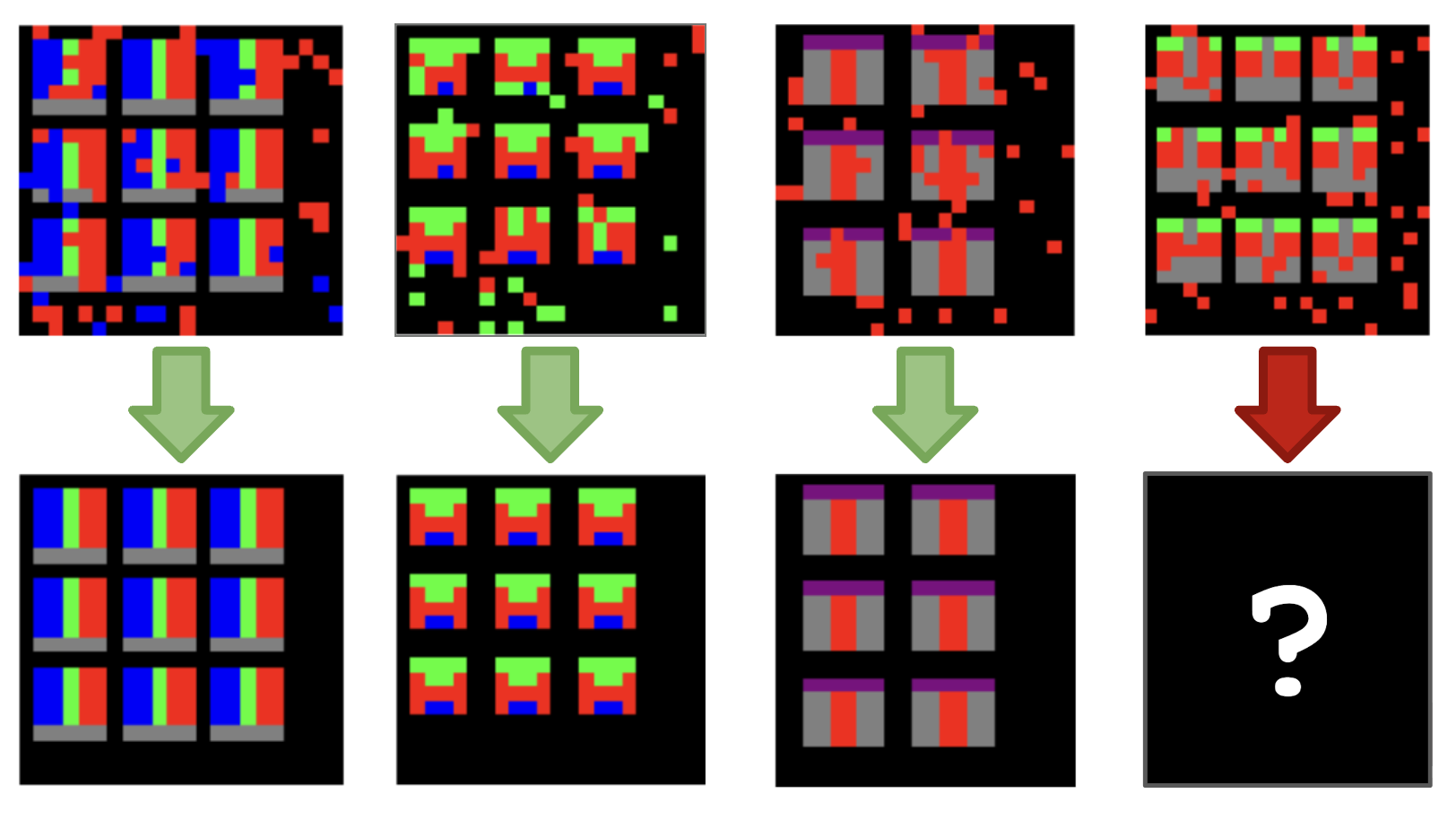
Movie Translation

Fictional Movie Language Translation (Avatar, LotR, Star Trek, GoT)
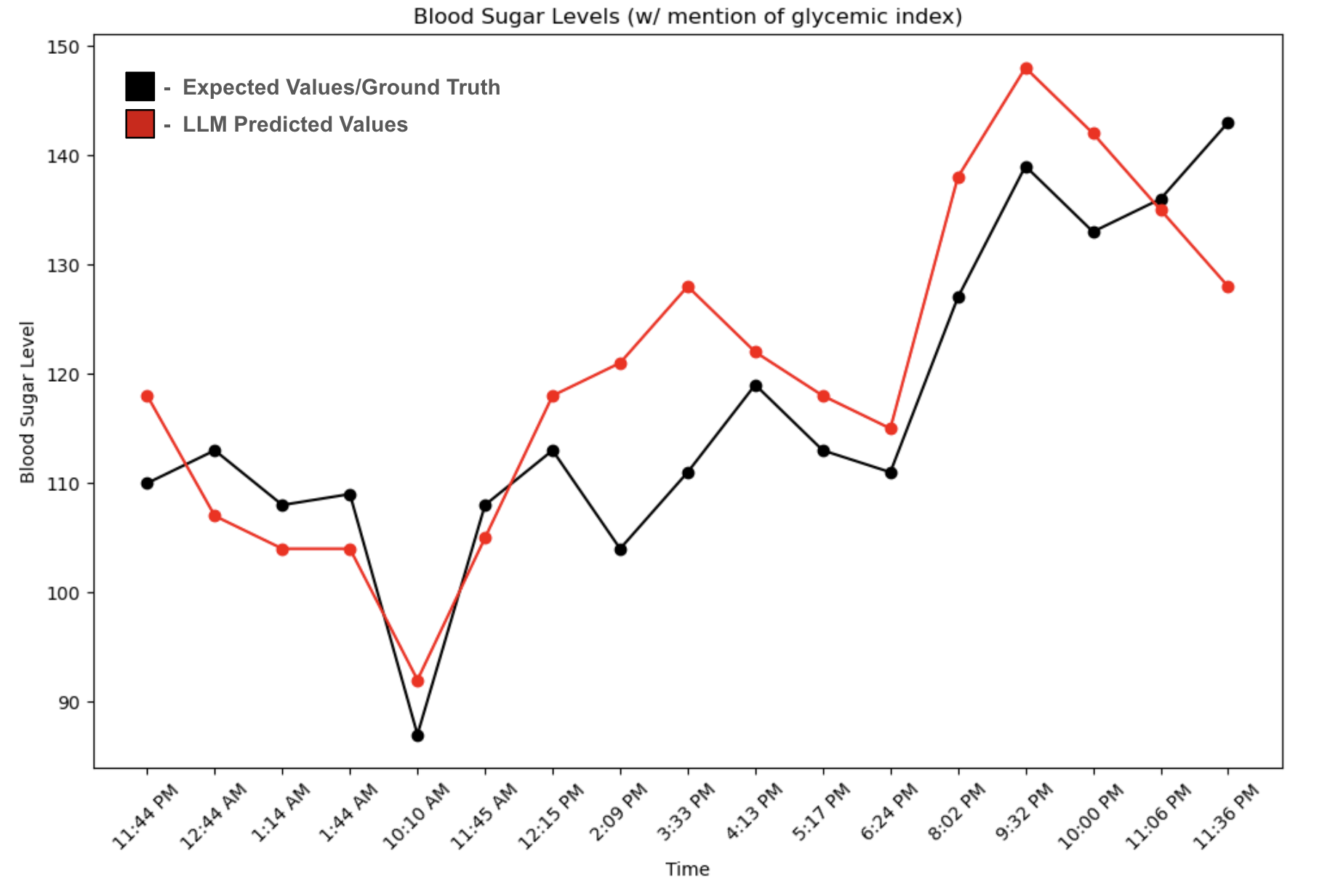


ProPS
"Reinforcement Learning using LLMs"
Utilization of Prompted Policy Search on MountainCar-v0
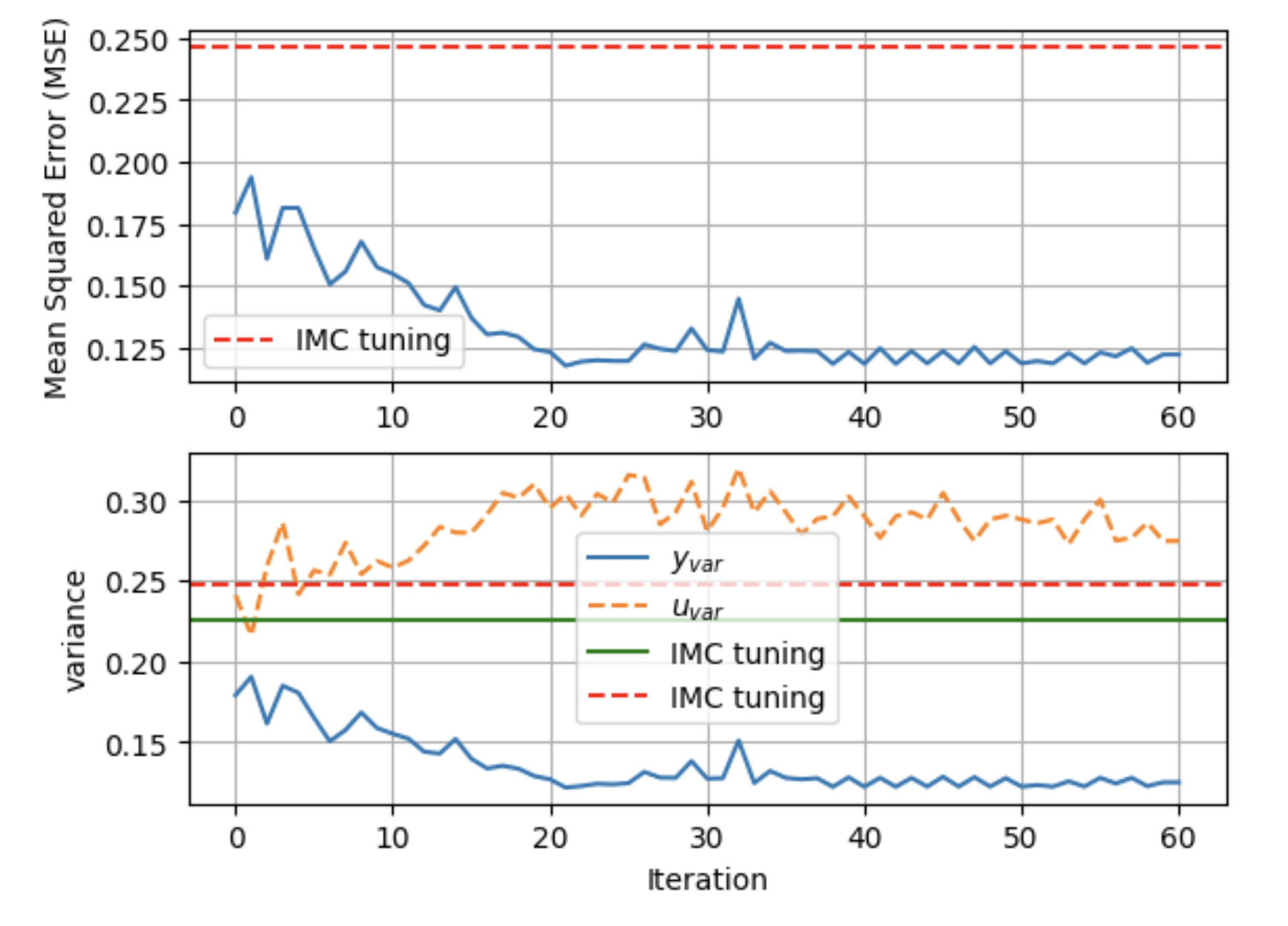
ProPS+
"RL using LLMs with Semantics"

Utilization of ProPS + Environment Description on Swimmer-v5
SAS-Prompt
"Self-Improvement using LLMs"
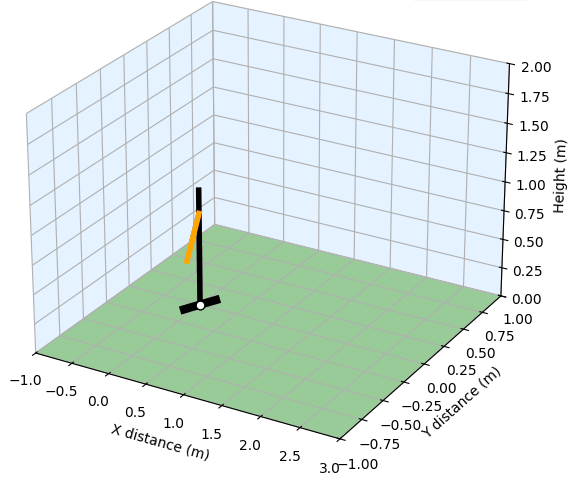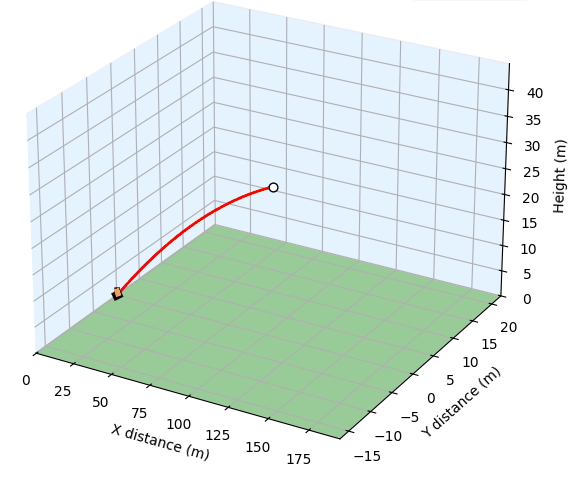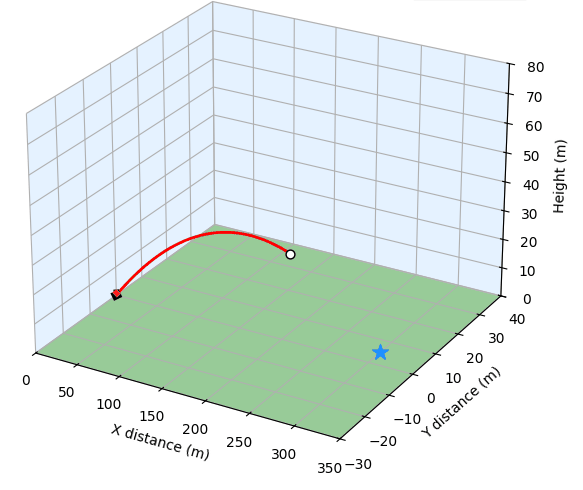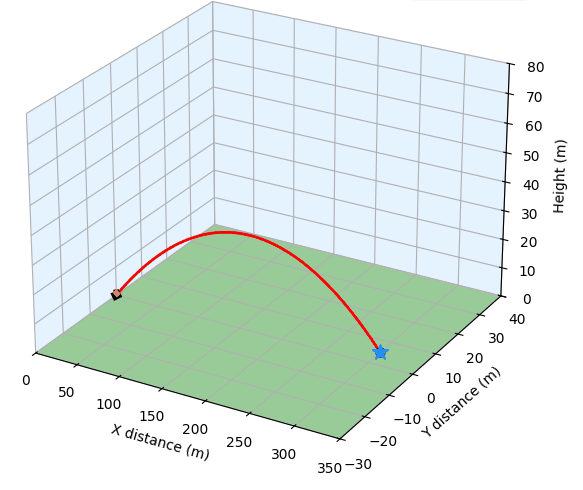
Implementation of SAS-Prompt through a Golf Simulation
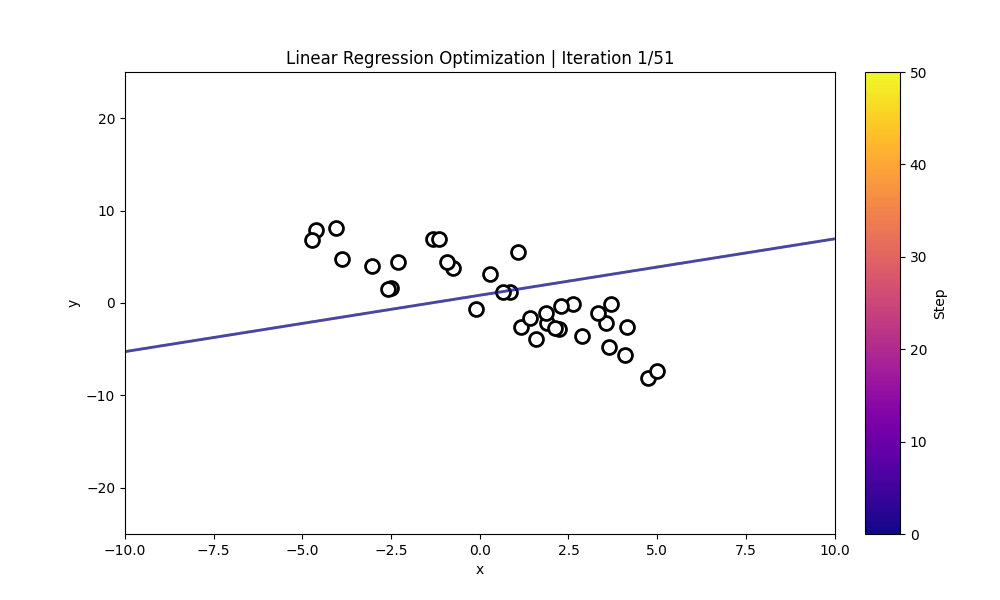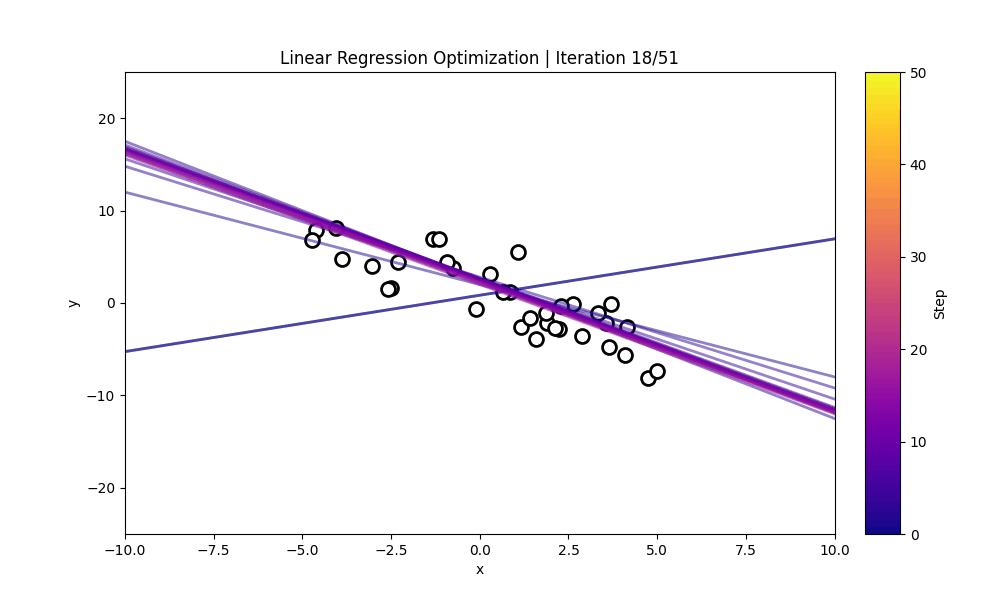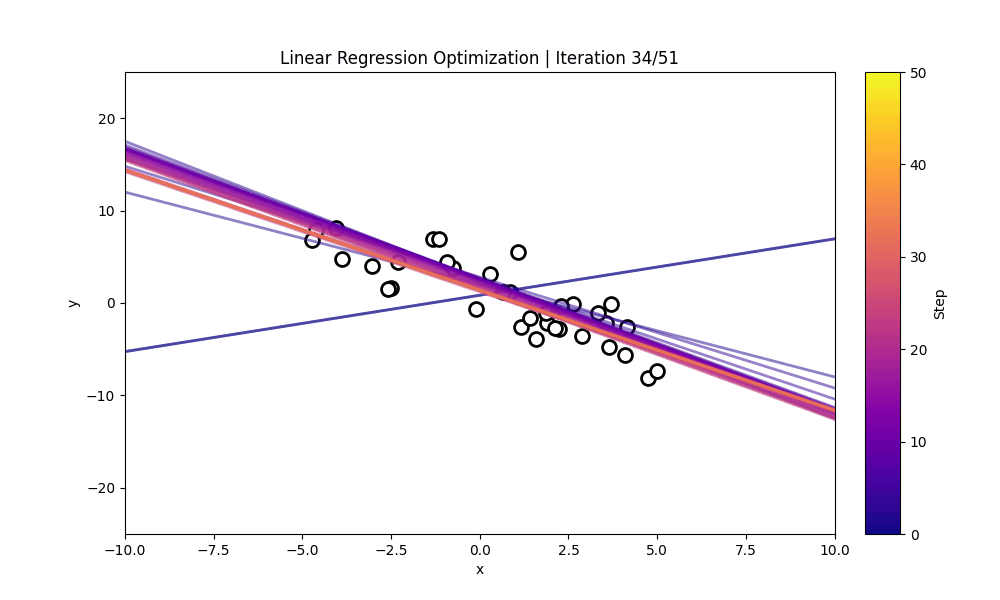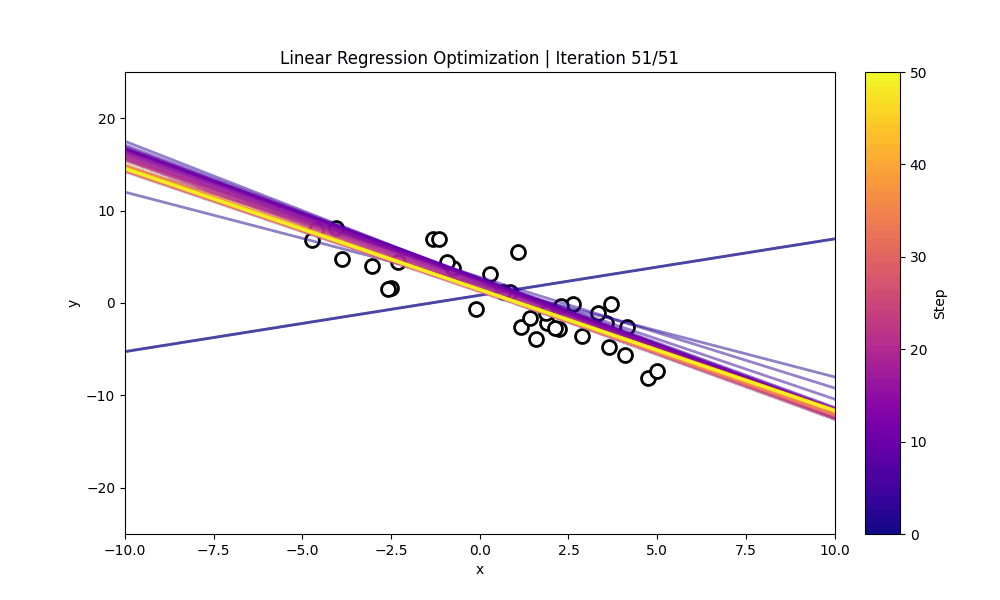
Numerical Optimization
"Numerical Optimization inside the LLM"
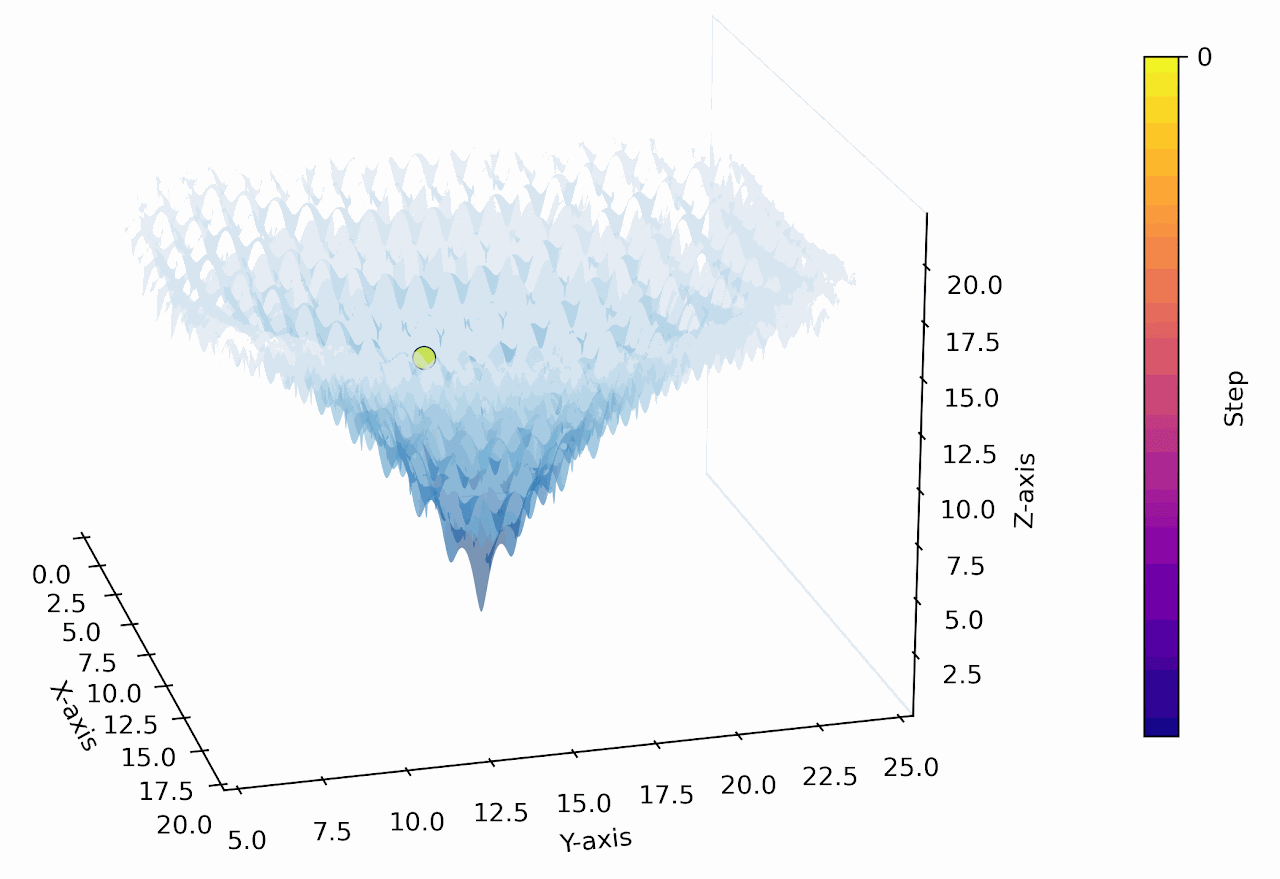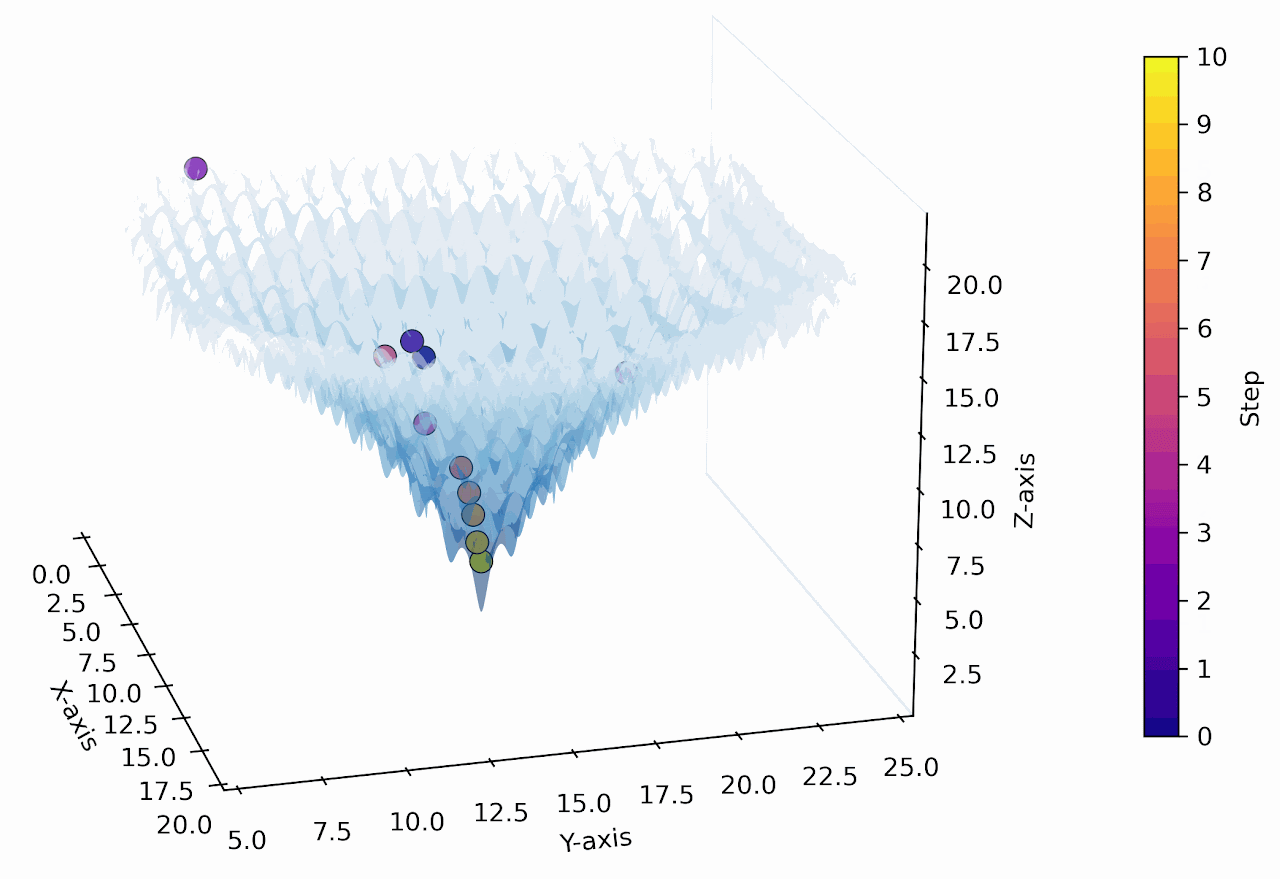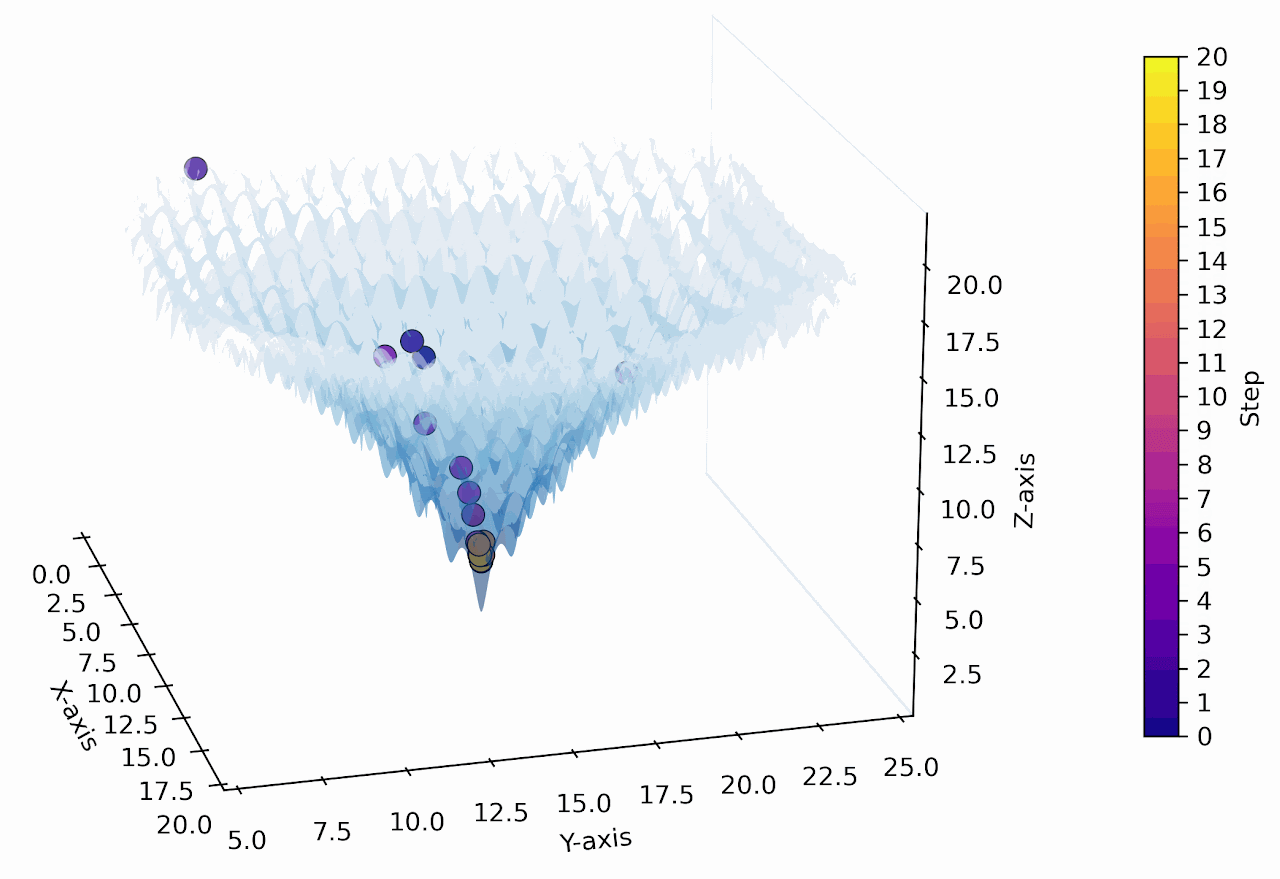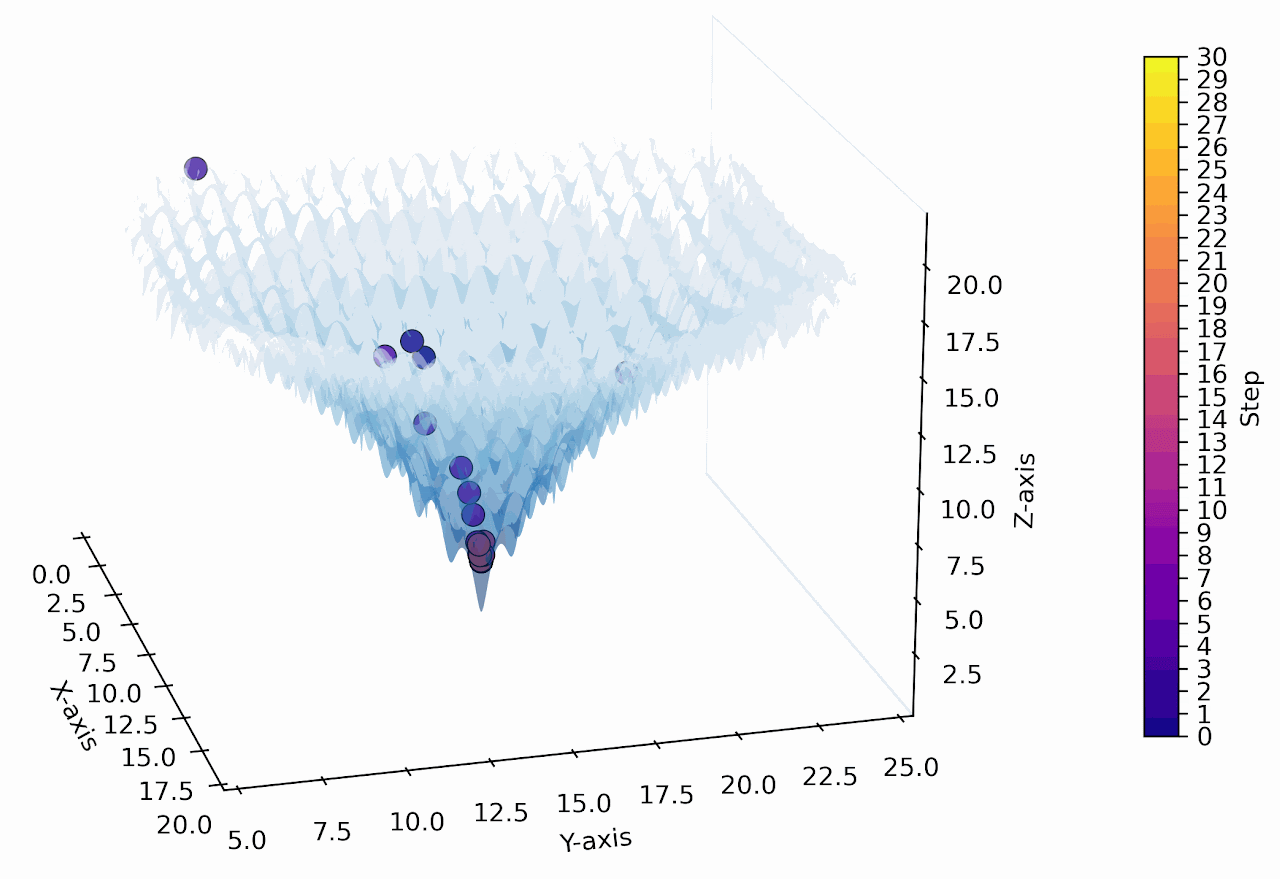
Numerical Optimization using the 1D & 2D Ackley Function
Acknowledgements
This work was supported by a charitable gift from Google DeepMind. We thank Google for the continued support of the Interactive Robotics Lab at Arizona State University.
This page was built using the Academic Project Page Template which was adopted from the Nerfies project page.
This website is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.