
Learning Through Context
In-Context Learning (ICL) is a powerful method that enables large language models (LLMs) to perform new tasks without modifying any of their internal parameters. Traditionally, LLMs are used as simple oracles: we pose a question, and they provide an answer. Recent work, however, shows that when we supply curated examples and engage the model iteratively, it can explore a broader solution space and progressively refine its reasoning. Unlike conventional machine learning pipelines—which rely on retraining, gradient updates, or fine-tuning on new datasets—ICL operates entirely through the input prompt. By embedding instructions, examples, or demonstrations directly into the text, we guide the model to infer patterns and adjust its output behavior dynamically. In this sense, the model “learns” in real time during the interaction, rather than through an offline training process[2].
One way to understand ICL is to think of it as “learning by showing”. When we present the model with a few input–output pairs that illustrate the task, the model analyzes the structure of the examples—how the inputs are transformed, what relationships matter, and what rules appear to be operating. Then, when faced with a new but related query, it extends or completes the pattern it has detected. For instance, if we show a few examples of converting informal text into formal prose, labeling sentiment, extracting key information, or solving a math pattern, the model can immediately generalize the behavior even with only a handful of samples.
A useful analogy is a child observing a simple block-stacking pattern. After watching someone arrange the blocks a few times, the child does not need a full explanation of physics or geometry to replicate the behavior—they simply infer the pattern from the demonstrations. Similarly, LLMs rely on their vast pre-training knowledge to interpret the examples we provide and map them to the task at hand. The examples in the prompt act as contextual training data, and the model leverages its internal representations to align with those examples, even though its core parameters remain unchanged.
Since ICL requires no training pipeline, it offers flexibility and efficiency. It allows rapid iteration, adapts to a wide range of tasks, and supports few-shot or even zero-shot generalization. This capability is one of the reasons modern LLMs are so versatile: they can flexibly shift between tasks—from classification and reasoning to translation and summarization—simply by receiving the right context.
How does In-Context Learning Work?
LLMs learn from examples by reading them as part of the input. The model looks for patterns, relationships, or rules that connect the example inputs to their corresponding outputs. Once it detects these patterns, it applies them to new information that's provided.
1. The Model Reads Examples Like a Story
When we give a sequence of examples, the model processes them just like reading sentences in a story. For example:
1 → 2
2 → 4
3 → 6
4 → ?The model processes these in order, identifies the underlying pattern—multiplying by two—and in this case, uses that pattern to generate the appropriate continuation, which would be 8.
2. The Model Detects Patterns
After being trained on vast and varied datasets, LLMs develop strong and highly flexible pattern-recognition abilities. During ICL, the model draws on this internal knowledge to compare the examples it’s given, noticing subtle relationships in structure, meaning, or logic. From there, it infers the underlying rule or process being demonstrated—whether that rule involves numerical relationships, text-to-text transformations, multi-step reasoning patterns, or even abstract visual or spatial structures. In essence, the model generalizes from the demonstration much like a human would: by recognizing what stays consistent across examples, identifying what changes, and mapping those insights onto the new input. This ability to fluidly extract patterns allows LLMs to perform new tasks on the fly without explicit retraining or access to labeled datasets.
3. The Model Completes the Pattern
After recognizing the pattern, the model continues it by applying the inferred rule to the new input. Once the relationship between the examples is clear, the model extends that logic in a consistent and coherent way. For example:
Translate to French:
cat → chat
dog → chien
bird → oiseau
horse → ?
Because it has identified that each English word is being mapped to its French equivalent, the model fills in the missing piece—horse → cheval—thereby completing the demonstrated pattern. This process is not limited to language translation; the same mechanism applies to mathematical sequences, stylistic transformations, logical reasoning steps, and many other pattern-based tasks.
4. No Training Required
Most importantly, the model isn’t being retrained. Its parameters remain completely unchanged throughout the process. Instead of updating its weights, the model leverages the knowledge and structures it already acquired during pretraining. ICL works because the model uses this internal understanding to align with the patterns demonstrated in the examples, effectively simulating task adaptation on the fly, making it feel adaptive even without any weight updates.
Simple Analogy
To understand how in-context learning works and how examples shape what pattern the LLM infers, consider this simple analogy with a child learning from drawings:
🍊 = orange
🍎 = red
🍌 = yellow
🍇 = ?
At first glance, the mapping 🍊 = orange is ambiguous. “Orange” could refer to the fruit or the color, so the child doesn’t yet know whether the pattern is “fruit → name of the fruit” or “fruit → color of the fruit.”
But the next two examples remove the ambiguity: Neither “red” nor “yellow” is the name of those fruits, so the child can infer that the pattern must be fruit → color rather than fruit → fruit name. With the pattern clarified, the child can now confidently continue it:
🍇 = purple
Now, lets flip it around so the context examples given reflect the fruit name rather than the color.
🍊 = orange
🍎 = apple
🍌 = banana
🍇 = ?
In this case, because the second and third examples use fruit names rather than colors, the child infers the mapping is fruit → name of the fruit, instead of fruit → color. So:
🍇 = grape
This is exactly how in-context learning works. When an LLM sees ambiguous examples, several interpretations may fit; but clear, consistent demonstrations push the model toward the intended pattern. The model infers the “rule” purely from context, so choosing representative examples is crucial. And when ambiguity can’t be avoided, adding a short instruction—like “map fruit to color” or “map fruit to name”—helps steer the model toward the correct task.
In-Context Learning vs. Traditional ML
Traditional Machine Learning: “Learn First, Use Later”
In traditional machine learning, the process is divided into two major phases. The first phase is training, where the model uses a large training dataset to adjust—and continually update—its internal parameters, such as weights and biases. This optimization process is computationally expensive and can take hours, days, or even weeks.
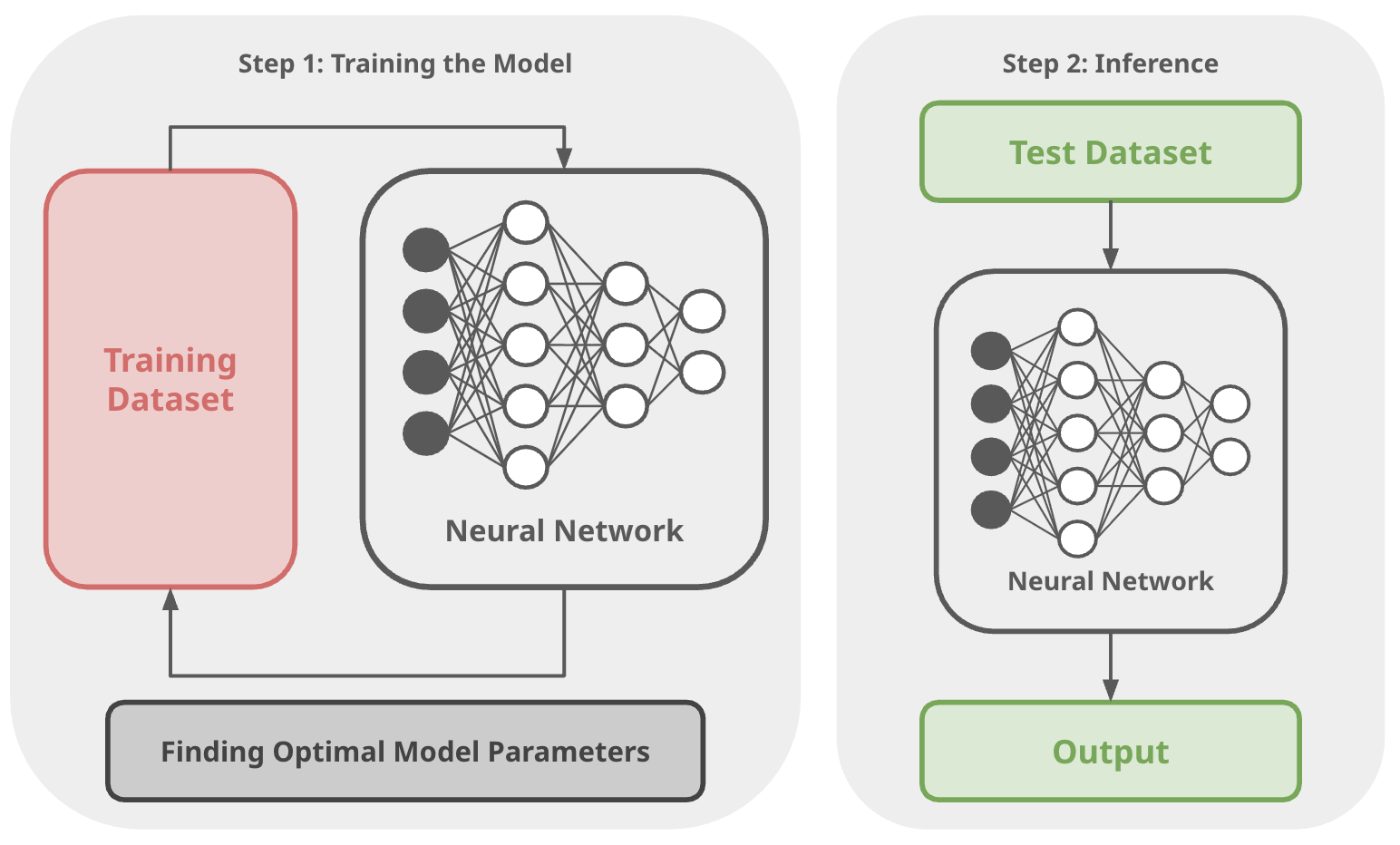
In this phase, a large dataset is fed into the model, and its internal parameters—weights and biases—are adjusted over many training cycles. The objective is to learn an optimal set of parameters that enables the model to make accurate predictions across a wide range of inputs. Because this optimization process is slow and computationally intensive, it is typically performed only once prior to deployment.
Think of this like a student studying for a final exam:- They ① read books, ② take notes, ③ do practice problems, and ④ slowly update their understanding over time.
After the model has been fully trained, it receives new input queries and generates outputs without altering any of its parameters. Instead, it relies entirely on the knowledge encoded in its trained weights to produce predictions or responses. At this stage, the model’s behavior is fixed, drawing solely on what it learned during the training phase.
Think of this like a student taking a final exam:- They ① can't study anymore and ② must rely on what they learned earlier.
In-Context Learning: “Learn While You Read”
In contrast, In-Context Learning (ICL) allows a model to adapt its behavior during inference without modifying its internal parameters. Instead of retraining the model, we provide examples, instructions, or demonstrations directly inside the input prompt. These elements become the “context” that guides the model’s reasoning.
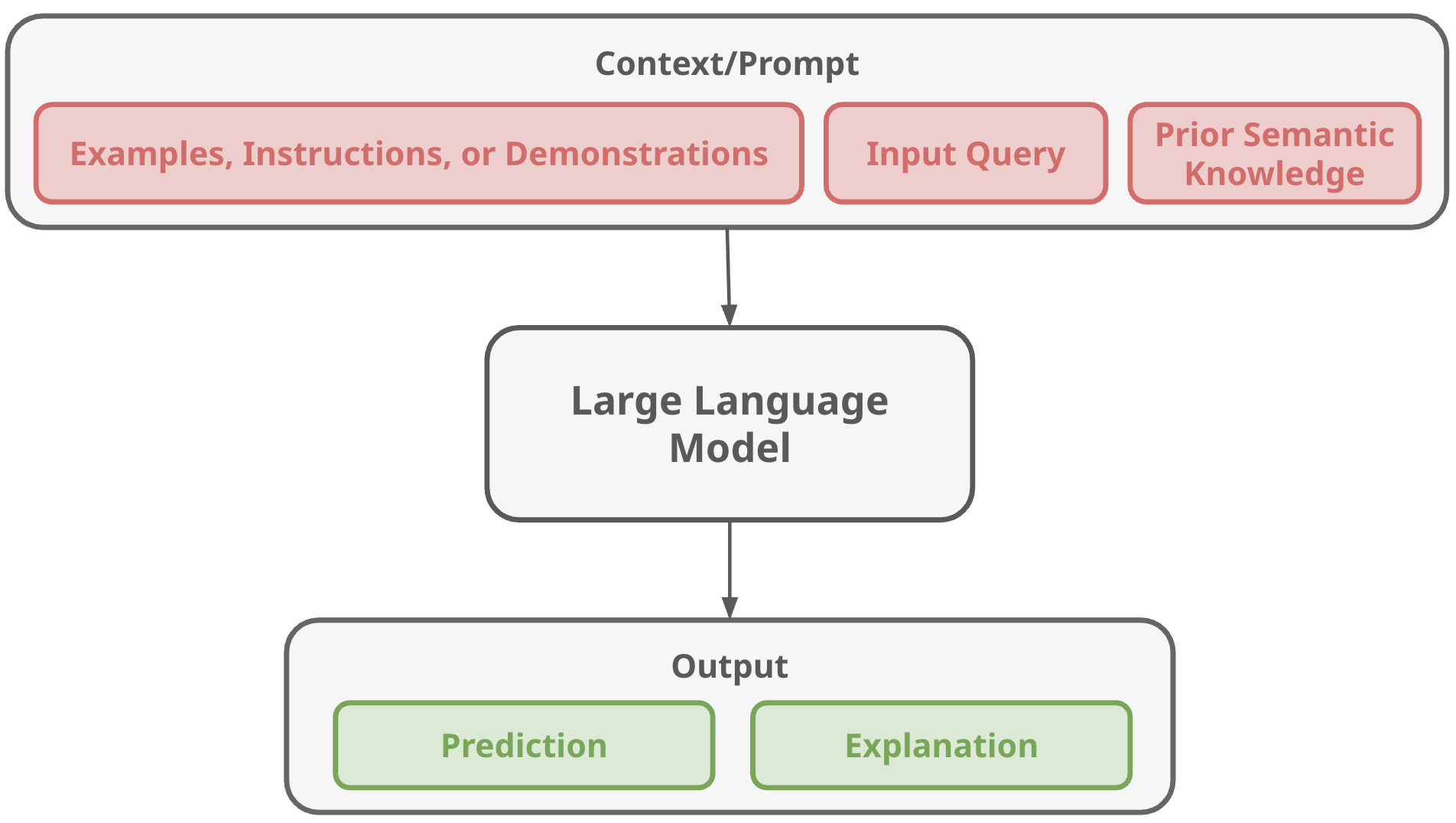
Instead of retraining the model, we provide it with context directly inside the input prompt—such as examples, instructions, demonstrations, and the user’s query. The model then draws on its pretrained knowledge, the examples included in the prompt, and the current input to combine all of this information during inference, generating both an output and, in some cases, an explanation. Unlike traditional machine learning approaches, In-Context Learning does not update the model’s weights; everything happens dynamically “in the moment” within the prompt window.
Think of this like giving a student a cheat sheet during an exam:- ① They don’t update their long-term memory but ② can follow the examples provided to solve the problem.
The model uses a combination of its pretrained knowledge, the examples provided in the prompt, and the user’s input query to generate both an output and, optionally, an explanation. Importantly, the model’s parameters remain unchanged. All adaptation happens dynamically inside the context window.
Lets Get Started with a Simple Demo
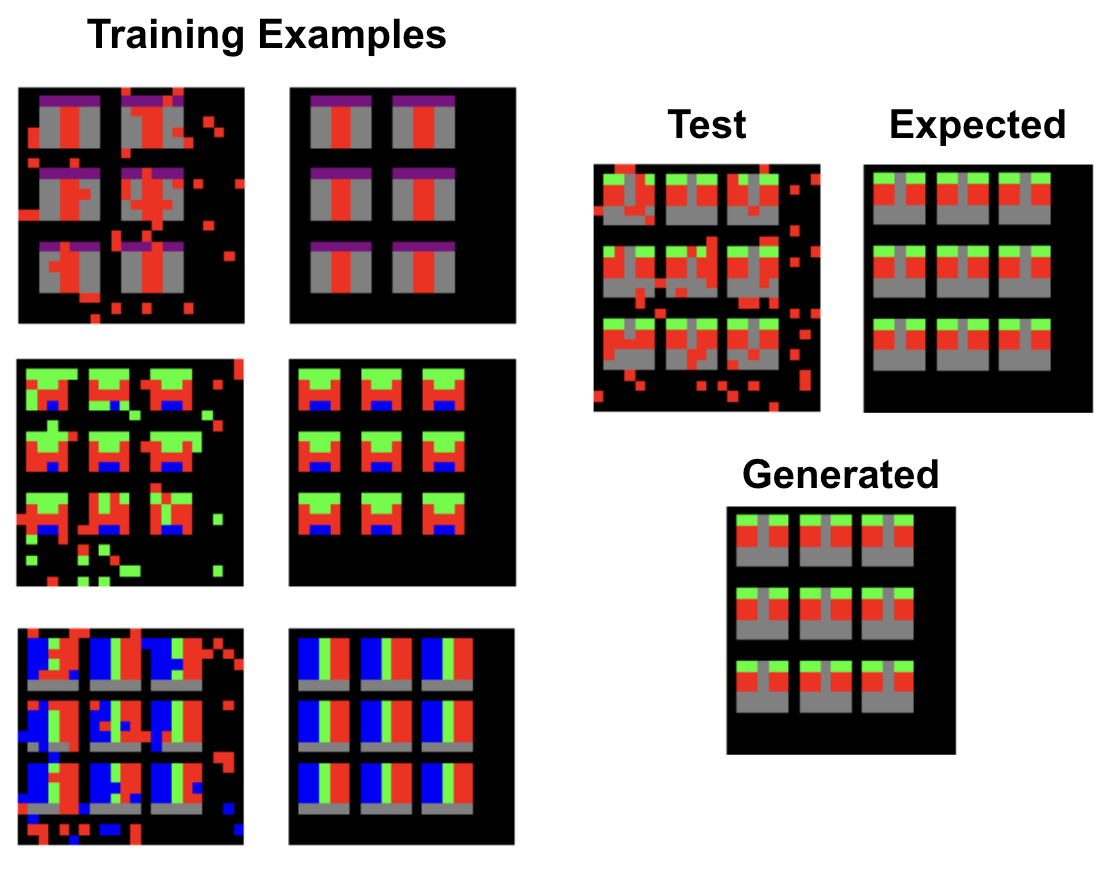
This demo illustrates how LLMs can utlize ICL, inspired by Large Language Models as General Pattern Machines (Mirchandani et al., 2023). To showcase this, we use tasks from the Abstract and Reasoning Corpus (ARC), introduced in On the Measure of Intelligence (Chollet, 2019), a benchmark designed to test a system’s ability to perform human-like reasoning on small, symbolic grids. Each ARC task contains a set of colored grids that transform according to a hidden rule. To teach the model this rule, we present three input–output example pairs. These examples demonstrate how the transformation works—whether it involves moving objects, changing colors, detecting symmetry, or applying geometric operations.
After seeing the examples, the model is given a new test input grid and must generate the correct output grid by inferring the underlying pattern and applying it consistently. In this demo, the Gemini 2.5-Flash model performs the reasoning and produces the predicted output grid.
How Does This Compare to Traditional ML?
In a traditional machine learning workflow, learning this hidden rule would require training or fine-tuning a model on many examples so its parameters can gradually adjust to the task. If you introduced a new ARC puzzle with a different transformation rule, the model would typically need more labeled data or another round of training.
ICL works very differently. The model doesn’t update its parameters at all. Instead, it “learns” the rule purely from the three examples placed in the prompt. The reasoning happens dynamically at inference time: the model observes the pattern, infers the transformation logic, and applies it to the new grid—just as a person might.
The example image below lets you browse through the provided demonstrations. Use the arrows to explore each input–output example and observe how the LLM generalizes the rule to new cases.
Summary & Key Differences
Traditional machine learning and in-context learning differ fundamentally in how they adapt to new tasks. In traditional ML, learning happens during training, and inference simply applies whatever the model learned previously; updating the model for new tasks requires adjusting its parameters, which is slow and computationally intensive. In contrast, ICL exhibits learning-like behavior during inference by using contextual examples, meaning no retraining is needed—changing the prompt is enough to adapt the model to new situations. A helpful way to think about this distinction is that traditional ML requires “studying ahead of time,” while ICL enables the model to “learn from examples in the moment.”
ICL offers several advantages over traditional approaches. It enables fast adaptation, allowing the model to perform new tasks instantly without retraining. Because the model’s parameters remain unchanged, there is no risk associated with altering its core behavior. ICL is also highly flexible, working across text, numbers, code, and even abstract patterns, and it often requires only a small number of demonstrations—sometimes just a single example—to be effective.
References
Mirchandani, S., Xia, F., Florence, P., Ichter, B., Driess, D., Arenas, M.G., Rao, K., Sadigh, D. and Zeng, A. (2023, December). Large Language Models as General Pattern Machines. In Conference on Robot Learning (pp. 2498-2518). PMLR.
Chollet, F. (2019). On the Measure of Intelligence. arXiv preprint arXiv:1911.01547.
This page was built using the Academic Project Page Template which was adopted from the Nerfies project page.
This website is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.